装软件
Build Xpdf:
1
2
3
4
5
6
7
8
| cd xpdf-3.02
sudo apt update && sudo apt install -y build-essential gcc
./configure --prefix="$HOME/fuzzing_xpdf/install/"
make
make install
|
Time to test the build. First of all, You’ll need to download a few PDF examples:
1
2
3
4
5
6
|
cd $HOME/fuzzing_xpdf
mkdir pdf_examples && cd pdf_examples
wget https://github.com/mozilla/pdf.js-sample-files/raw/master/helloworld.pdf
wget http://www.africau.edu/images/default/sample.pdf
wget https://www.melbpc.org.au/wp-content/uploads/2017/10/small-example-pdf-file.pdf
|
Ex1
CVE-2019-13288
AFL++
First of all, we’re going to clean all previously compiled object files and executables:
清理编译信息
1
2
3
4
|
rm -r $HOME/fuzzing_xpdf/install
cd $HOME/fuzzing_xpdf/xpdf-3.02/
make clean
|
And now we’re going to build xpdf using the afl-clang-fast compiler:
使用afl-clang-fast 进行构建
1
2
3
4
5
6
| export LLVM_CONFIG="llvm-config-11"
CC=$HOME/AFLplusplus/afl-clang-fast CXX=$HOME/AFLplusplus/afl-clang-fast++ ./configure --prefix="$HOME/fuzzing_xpdf/install/"
make
make install
|
跑fuzzer
1
| afl-fuzz -i $HOME/fuzzing_xpdf/pdf_examples/ -o $HOME/fuzzing_xpdf/out/ -s 123 -- $HOME/fuzzing_xpdf/install/bin/pdftotext @@ $HOME/fuzzing_xpdf/output
|
-i:表示输入文件目录
-o:表示 AFL++ 将存储变异文件的目录 存放fuzz过程中出现的生成的queue、crash、hang等
-s:表示要使用的静态随机种子(AFL 使用非确定性测试算法,因此两个Fuzz会话永远不会相同。这就是为什么设置固定种子 -s 123的原因。用以保证Fuzz结果和示例相同。)
@@:是占位符目标的命令行,指代文件,如果不加@@就是标准输入
-S:指定多开fuzzer就可以同时进行多个fuzzer 可以用htop查看一下当前的资源情况
分析Fuzz表
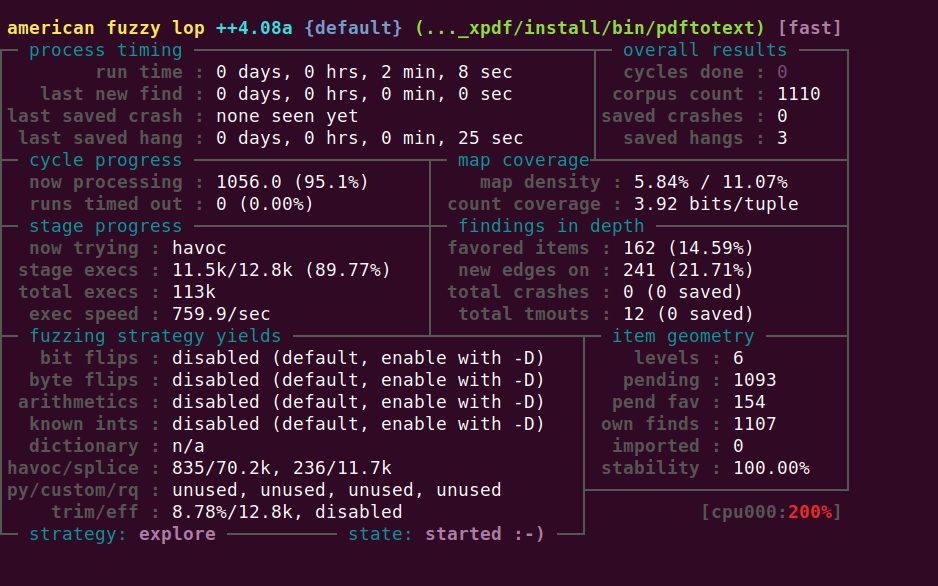

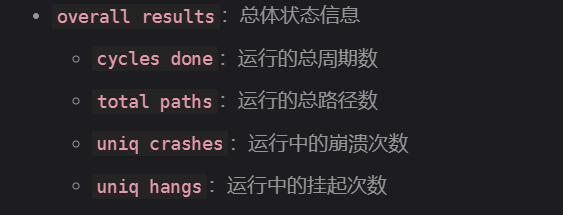
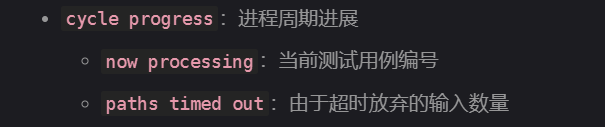

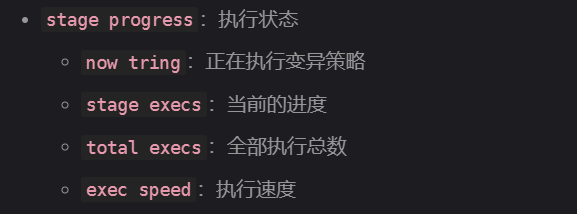



测试错误信息
1
2
3
4
5
6
7
8
9
10
| $HOME/fuzzing_xpdf/install/bin/pdftotext $HOME/fuzzing_xpdf/out/default/crashes/<your_filename> $HOME/fuzzing_xpdf/output
|
首先,重建 Xpdf 以获取符号堆栈跟踪:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
|
rm -r $HOME/fuzzing_xpdf/install
cd $HOME/fuzzing_xpdf/xpdf-3.02/
make clean
CFLAGS="-g -O0" CXXFLAGS="-g -O0" ./configure --prefix="$HOME/fuzzing_xpdf/install/"
make
make install
CFLAGS="-g -O0":这部分设置了 C 编译器标志(`CFLAGS`)。具体来说,它设置了两个标志:
`-g`:这个标志告诉编译器在生成可执行文件时包括调试信息,以便在调试程序时能够查看源代码和变量值。
`-O0`:这个标志告诉编译器不要进行任何优化。通常,优化可能会使生成的可执行文件更有效率,但在调试时可能会导致变量值不符合预期,因此 `-O0` 禁用了所有优化。
`CXXFLAGS="-g -O0"`:类似于上述 `CFLAGS`,这部分设置了 C++ 编译器标志(`CXXFLAGS`)。
`./configure --prefix="$HOME/fuzzing_xpdf/install/"`:这是一个常见的配置命令,用于准备软件的构建环境。`configure` 脚本根据您的系统和设置来配置软件以进行编译,并且通过 `--prefix` 选项指定了安装目录,将安装生成的文件到 `$HOME/fuzzing_xpdf/install/` 目录中。
|
run!
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
| gdb --args $HOME/fuzzing_xpdf/install/bin/pdftotext $HOME/fuzzing_xpdf/out/default/crashes/1.pdf $HOME/fuzzing_xpdf/output
`gdb`:启动 pwngdb 命令。
`--args`:`--args` 选项用于指定要调试的程序和它的命令行参数。
`$HOME/fuzzing_xpdf/install/bin/pdftotext`:这是要调试的程序的路径。
`$HOME/fuzzing_xpdf/out/default/crashes/<your_filename>`:这是作为命令行参数传递给 `pdftotext` 的输入文件的路径。确保将 `<your_filename>` 替换为实际的崩溃文件名。
`$HOME/fuzzing_xpdf/output`:这是输出目录的路径,我们希望在调试期间生成的任何调试信息的存储位置。
这个命令的作用是使用 `gdb` 来启动 `pdftotext` 程序,并将指定的输入文件传递给它,以便在调试期间分析和解决问题。
我们要确保替换 `<your_filename>` 为实际的崩溃文件名。
|
找洞过程
发现漏洞
我们输入
1
| $HOME/fuzzing_xpdf/install/bin/pdftotext $HOME/fuzzing_xpdf/out/default/crashes/<your_filename> $HOME/fuzzing_xpdf/output
|
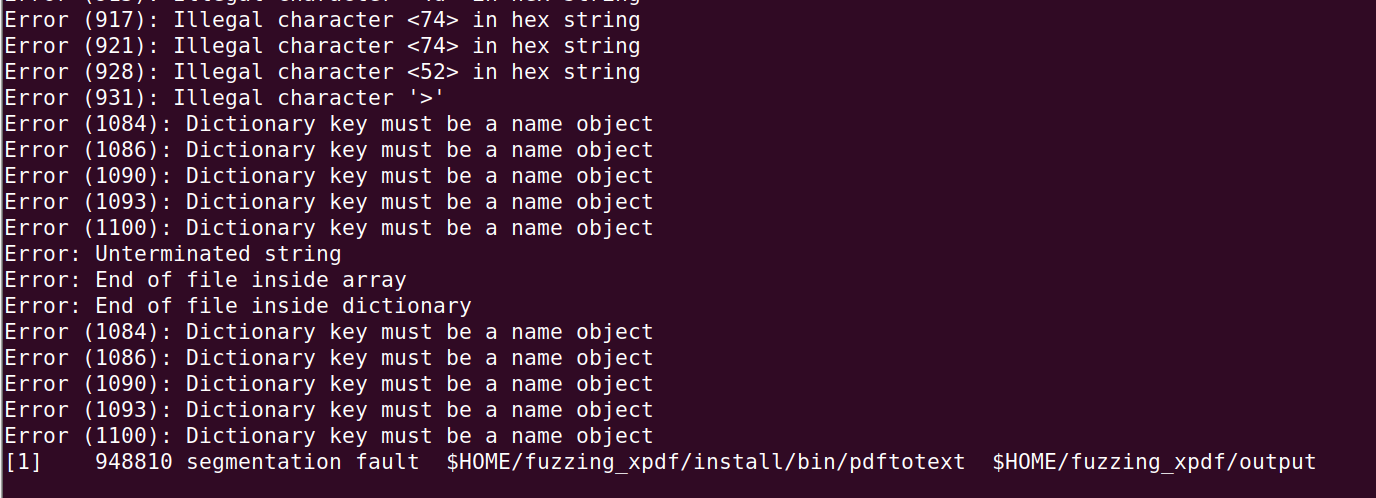
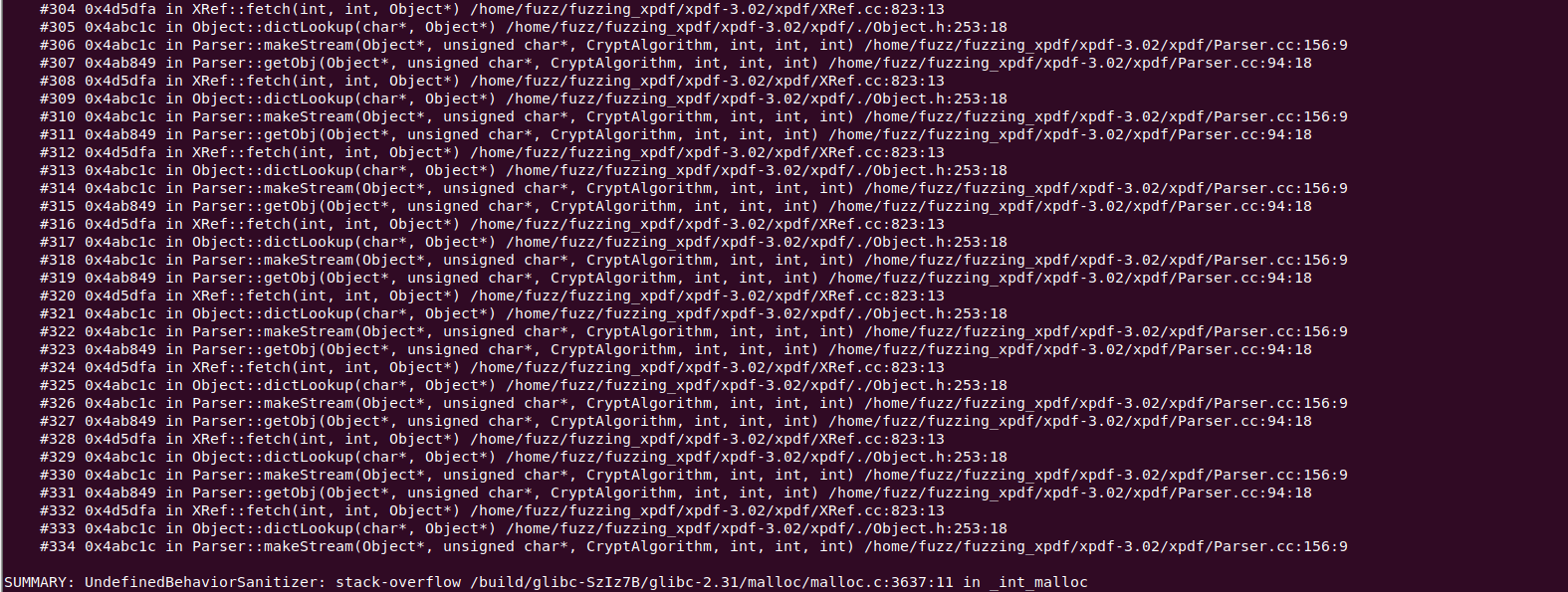
可以发现这里出现了问题 我们尝试使用gdb进入看一下
一定注意先 start 然后再run 直接run会直接退出来 程序崩溃
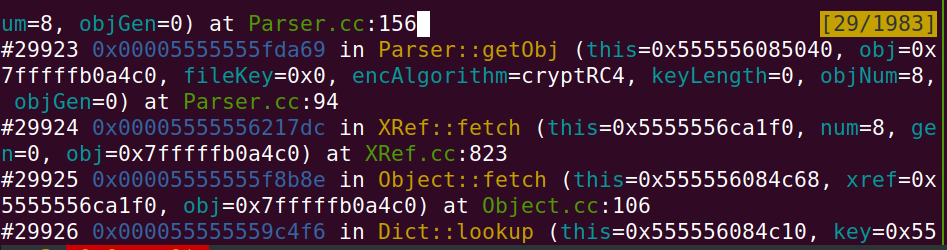
如图所示 我们能发现getObj函数 循环调用 我们知道不断运行函数时候 会一直分配栈帧 导致程序溢出出错 我们直接拎出来这段代码来看。我们这样看,并不知道到底怎么发生了无限调用,我们等会进行动态分析的时候会查看。
修复
我们首先拿出新旧版本的源码进行对比
我们发现 只是添加了一个 recursionLimit的参数 当我在困惑这个recursionLimit是怎么计算的时候 我发现 原来直接给了一个宏变量

直接给了 500的宏变量 限制了循环次数
细致分析
静态分析
追踪程序流

我们这里可以清楚的发现 这6个函数 会进行不断分析 我们试着去溯源分析一下这个函数是怎么调用的
我们猜测 XRef::fetch为该函数的起点 我们试着往上去找 这个函数 我们首先进入main函数搜索

无果
看来需要再找调用的地方
我们直接使用bt 追溯一下 看看如何调用 如图所示 但并未发现main函数在哪进入 但我们有新的发现

此时也是给了我们线索 但是我们还是无法回溯到main函数
我们尝试使用ida 找交叉引用
我们先找到Parser::getObj这个函数 然后往上追追试试
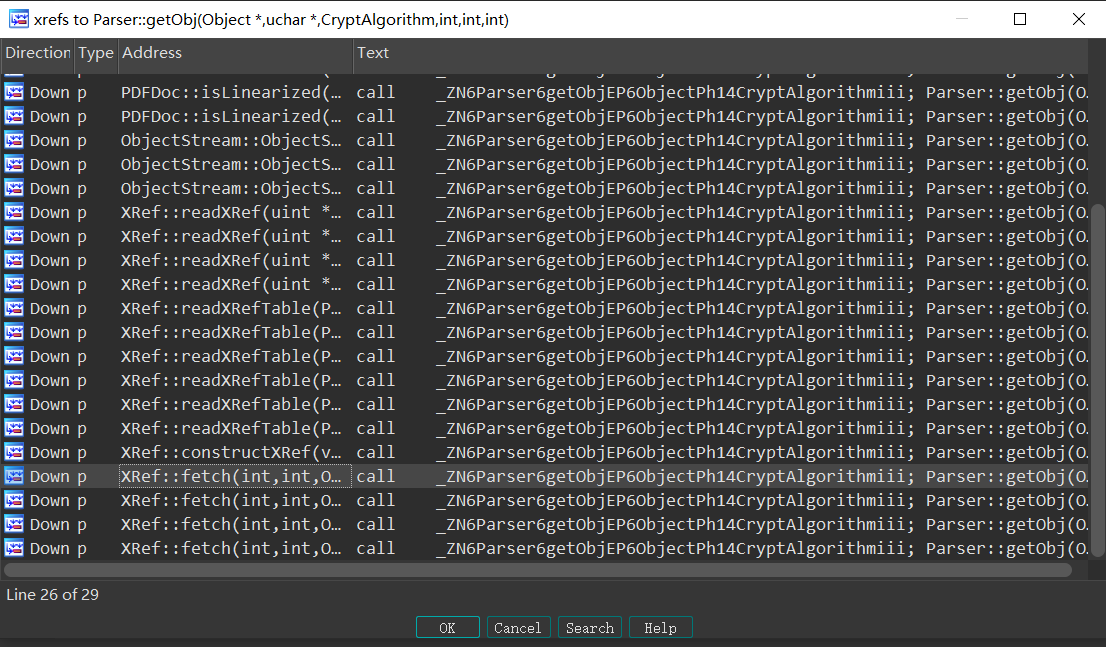
我们看到了熟悉的XRef::fetch 然后查看fetch 就步入试试

我们发现多次的引用
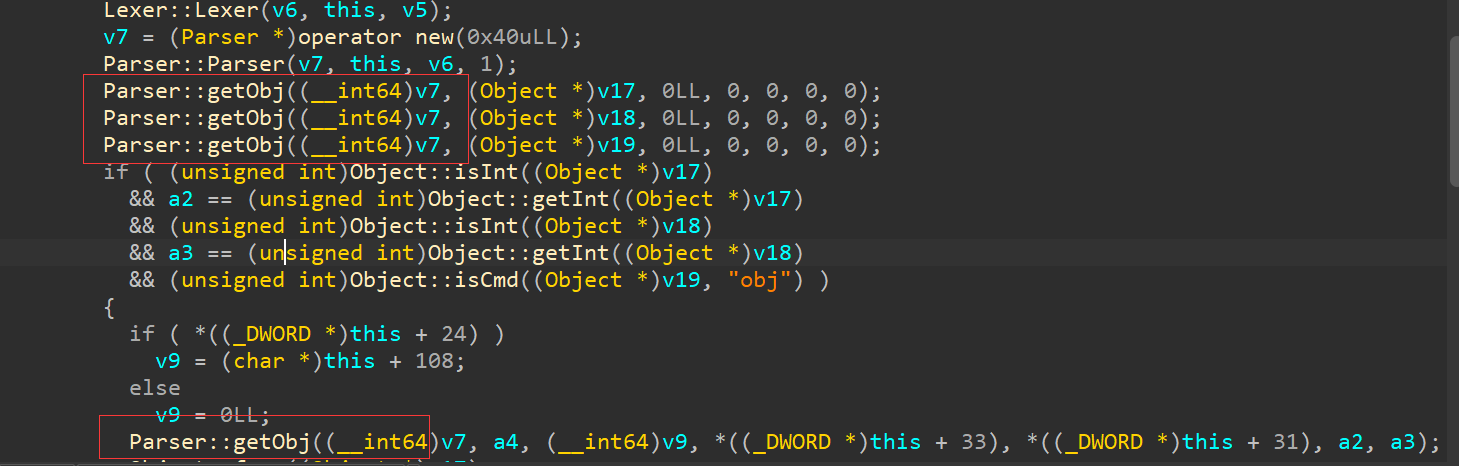
我们先不管 先继续往上找引用
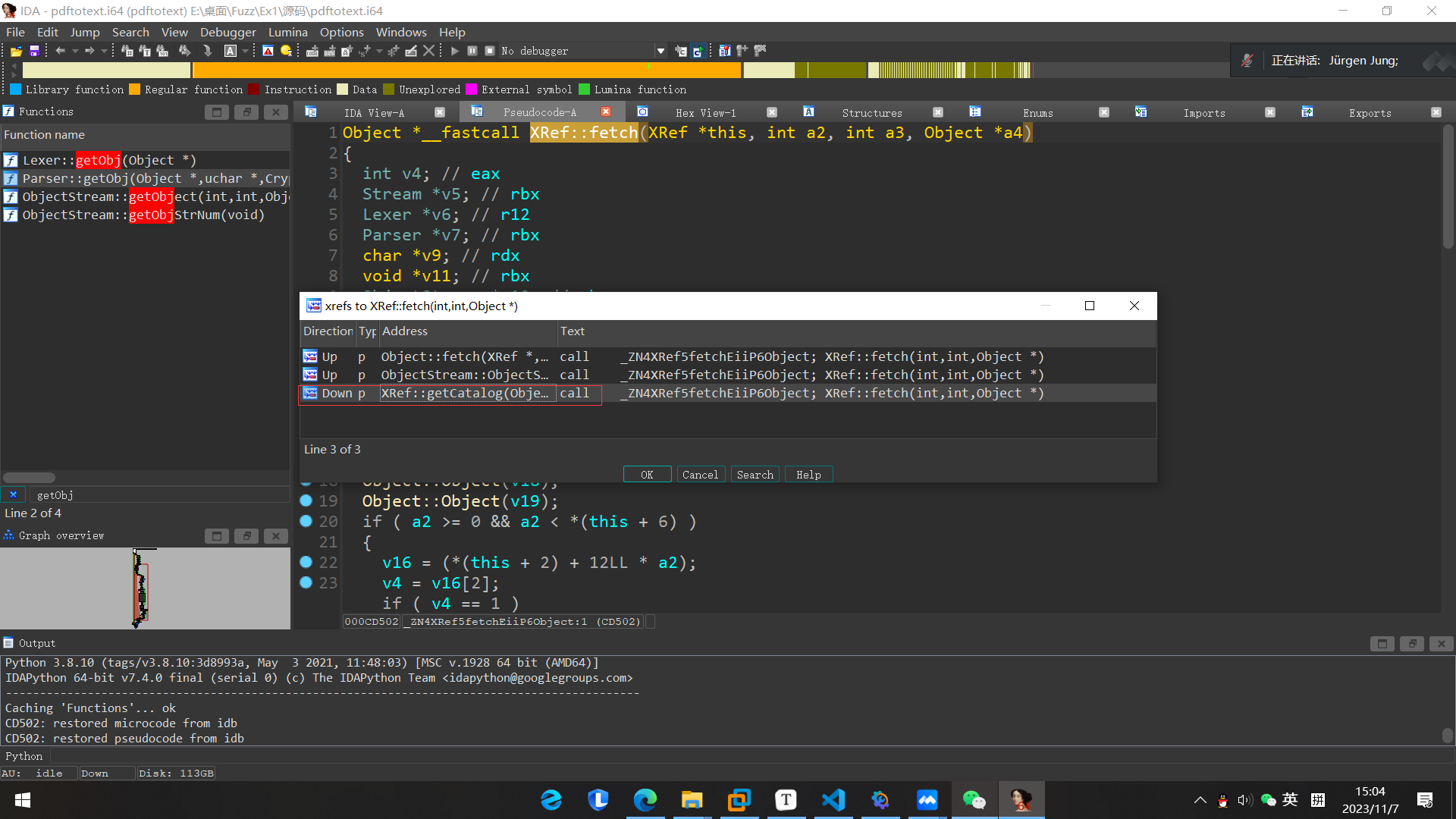
这里我们直接继续跟进XRdf::getCatalog试试

这个函数 也是非常的简单 我们接着往上找引用

我们看看Catalog::Catalog
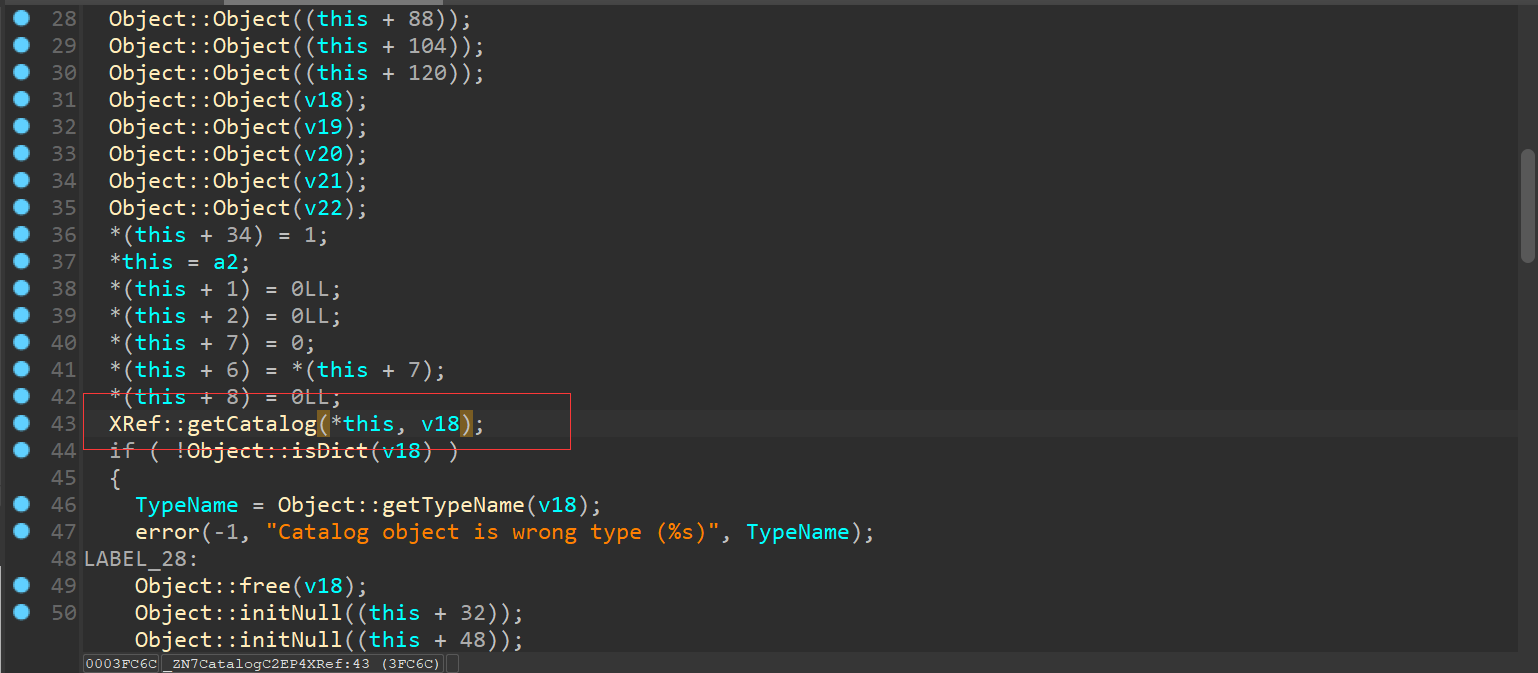
继续往上跟进

我们观察PDFDoc::setup继续跟
然后观察Page::PDFDoc
观察PDFDoc::PDFDoc之后
我们继续跟

我们也是成功的来到了main函数中
这样我们就大致完成了 程序流的跟踪
我们从前往后开始分析源码后发现程序的执行流是这样的
1
2
| main———>PDFDoc::PDFDoc———>PDFDoc::setup———>Catalog::Catalog———>XRdf::getCatalog———>XRef::fetch(5, 0, newobj)
———>Parser::getObj———>Parser::makeStream———>dict->dictLookup("Length", &obj)———>xRef->fetch(7, 0, newobj)
|
我们明白了程序流程以后 为我们就可以尝试开始进行数据流的分析了 看看我们如何来触发这个crash
动态分析
我们先找到程序断点 当我们不断ni 到这一步的时候 程序会自己断掉 我们步入看看情况
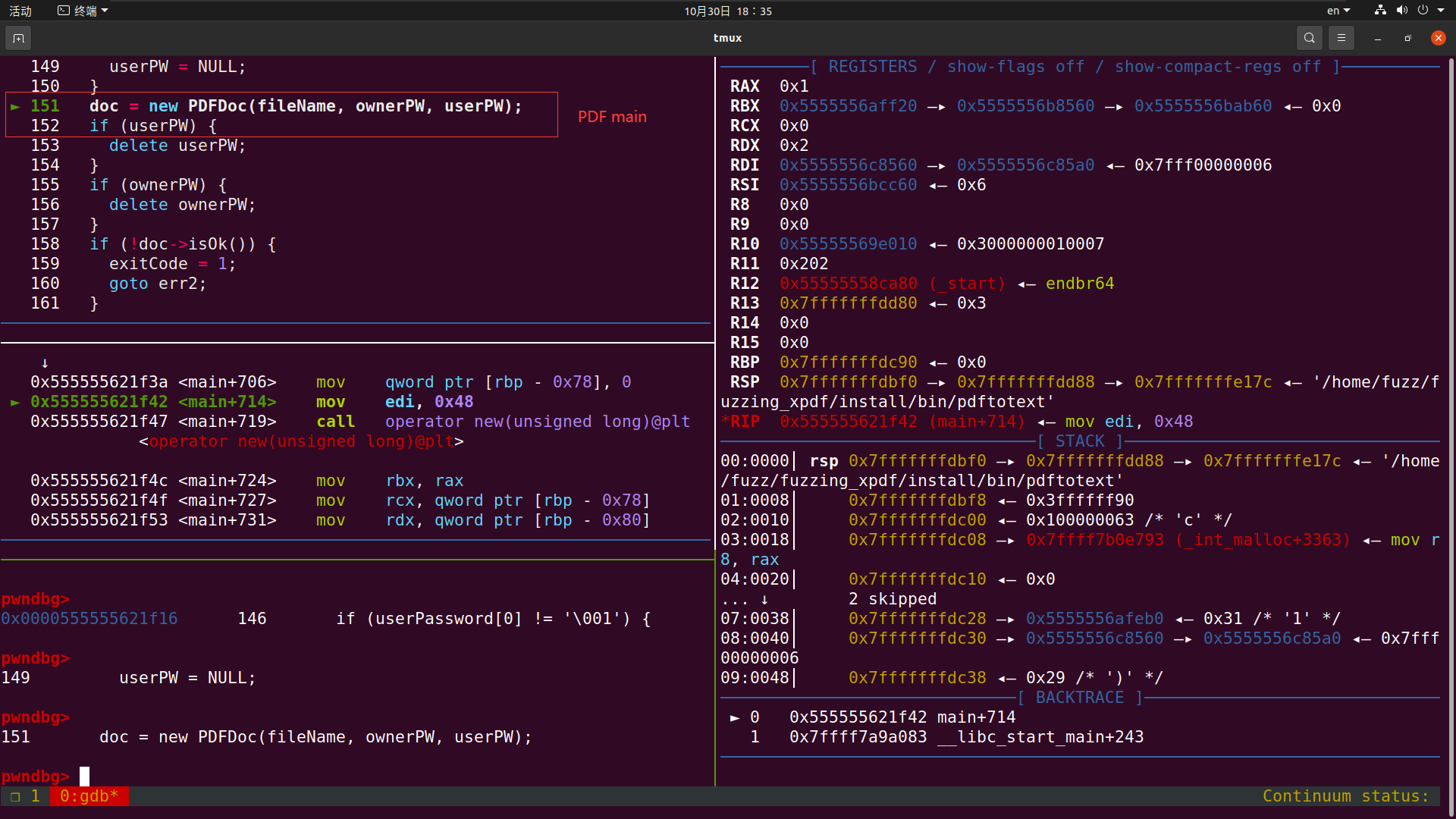
从这一步 步入函数
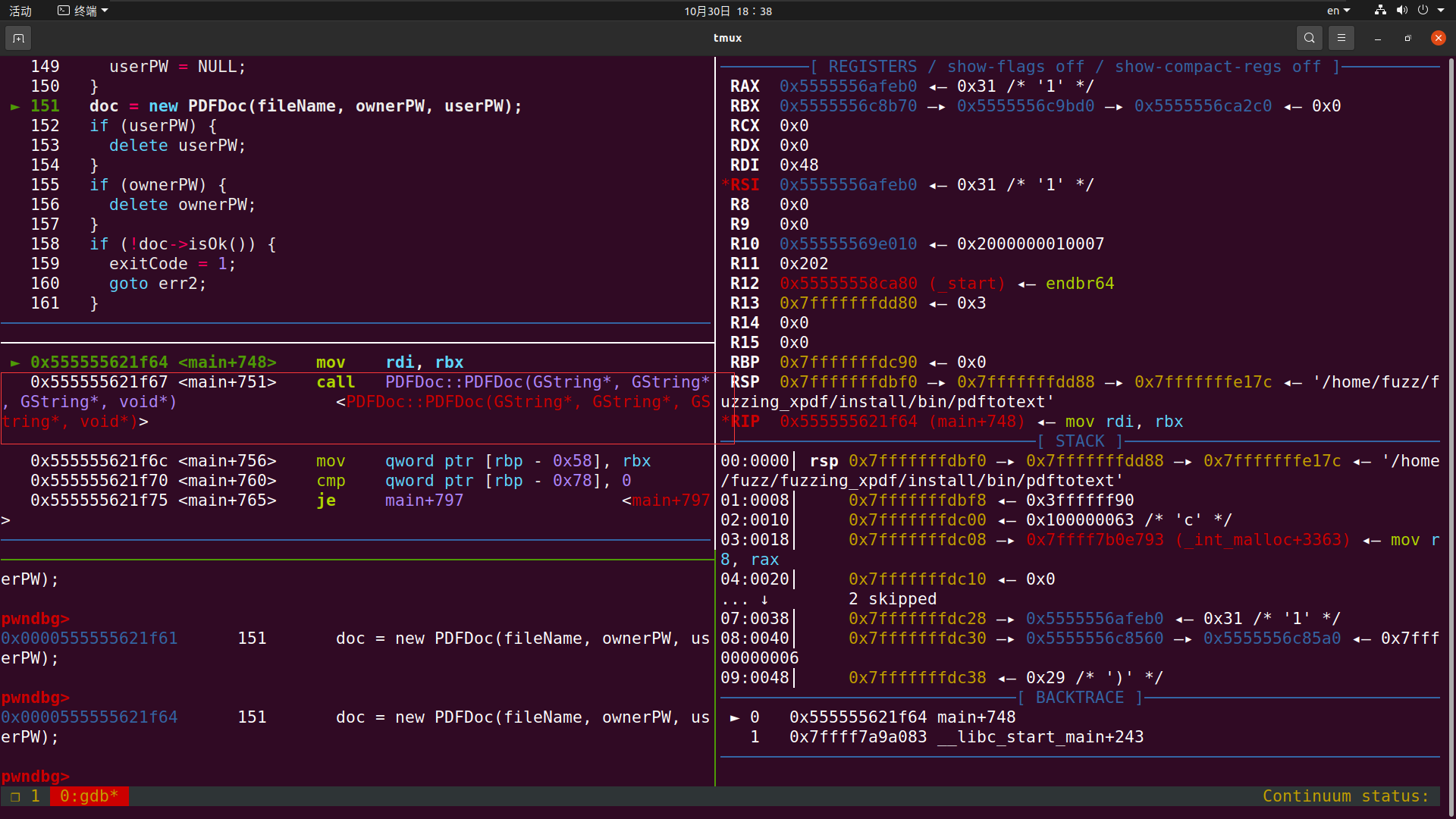
这里新建一个PDFDoc对象时 这时候我们打开PDFDoc来看 我们发现在这一步 也会导致程序崩溃
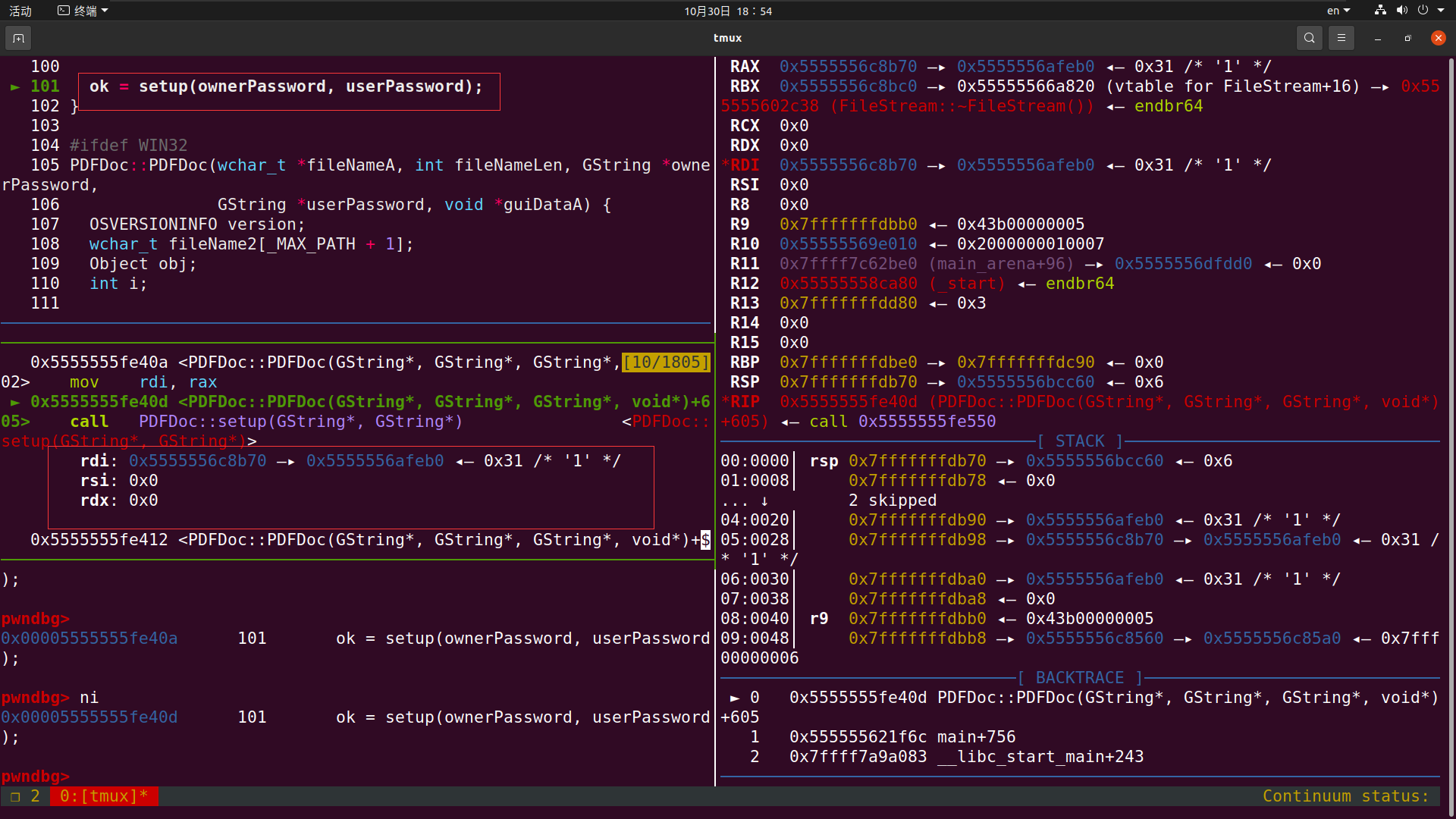
我们并没有传入密码 两项应该都为0 这个没问题
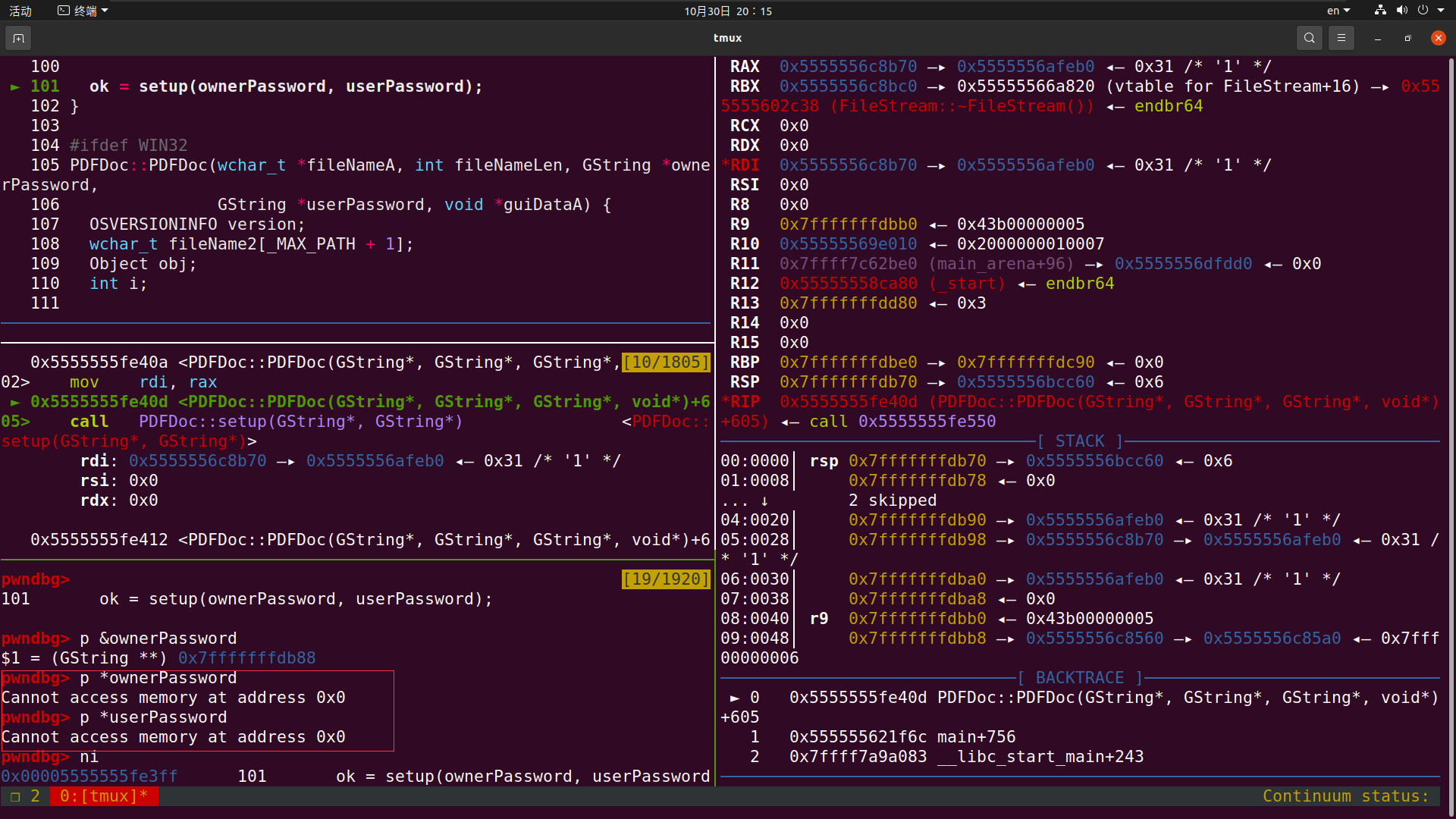
我们接着接着步入setup里面
首先进行检查head xref_table表
走到这一步 我们发现又创建了一个Catalog对象
这里我们跟进一下
进去以后我们会发现有一个 直接调用xRef的

我们在xRef.cc中并未找到这个类
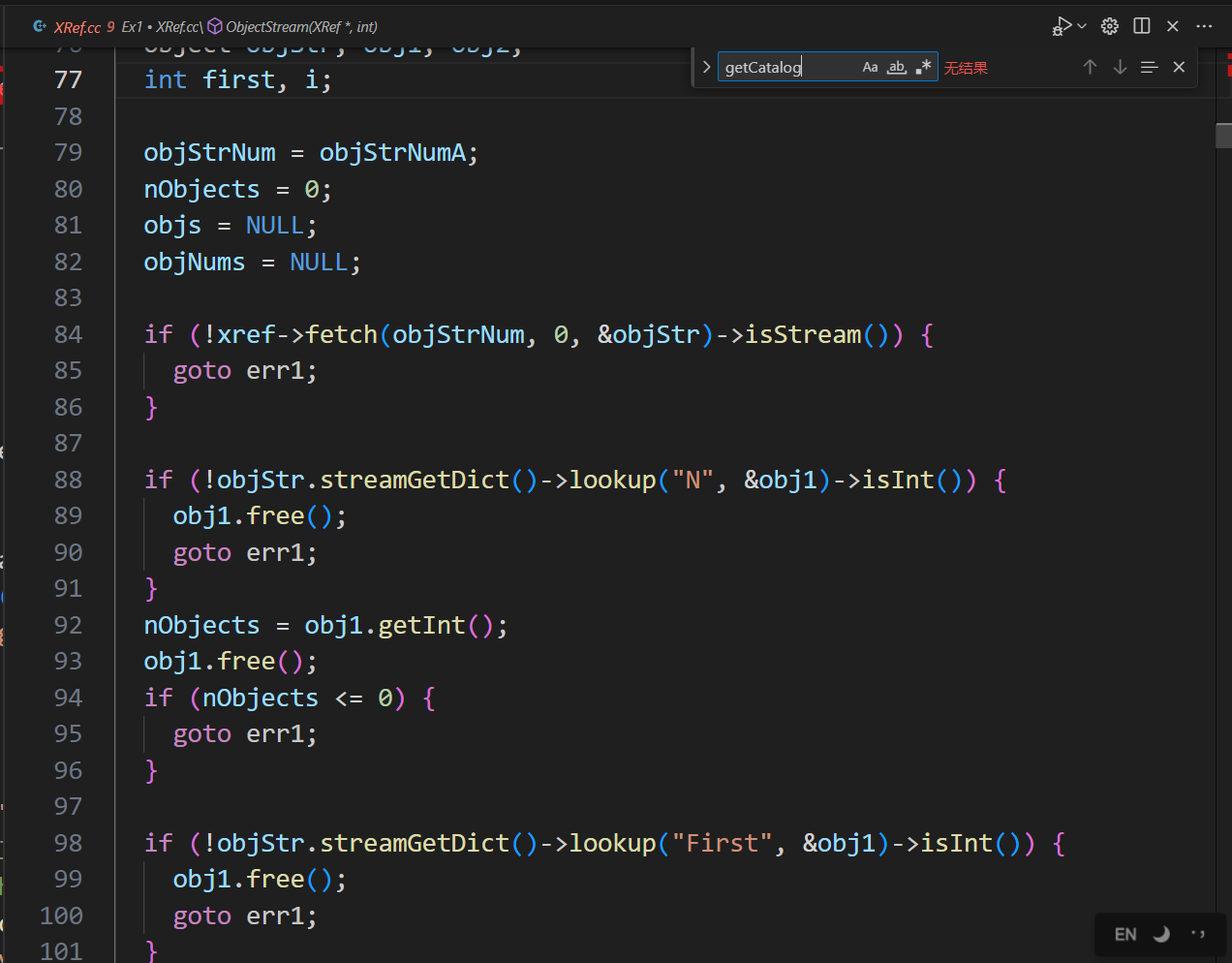
我们尝试去头文件里找一找,我们打开xRef.h 发现了如下定义

这时候我们相当于获得了一个Object::fetch
我们接着找Object::fetch
在Object.cc中我们找到了这段调用
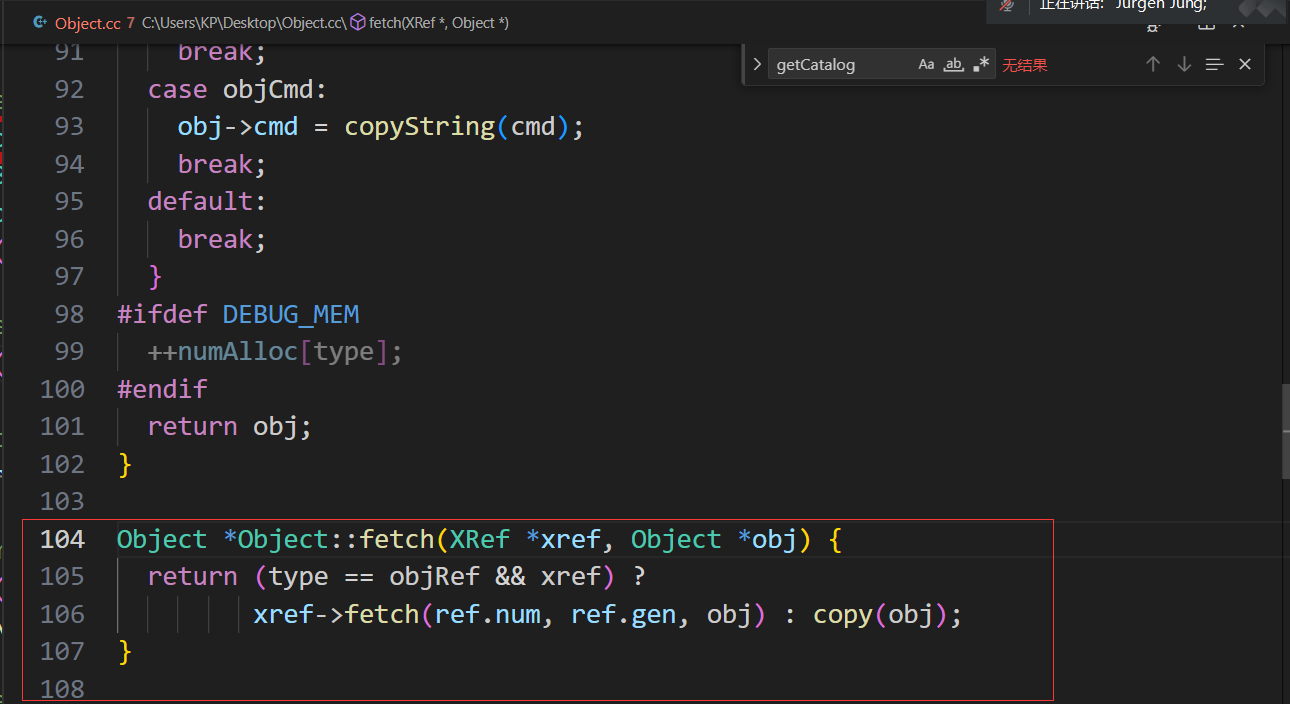
上面代码的含义如下:
如果当前 Object 对象是引用对象,并且存在有效的 XRef 对象 (xref 不为 nullptr),则调用 xref->fetch 方法来获取引用的对象;否则,可能执行一个复制操作(copy(obj))
通俗来说 也就是 将Object::fetch 封装为了xref——>fetch 然后往里面传入了参数ref.num ref.gen obj=&catDict
这里我们看到三个参数 分别为 5 0 0x7fffffffdab0
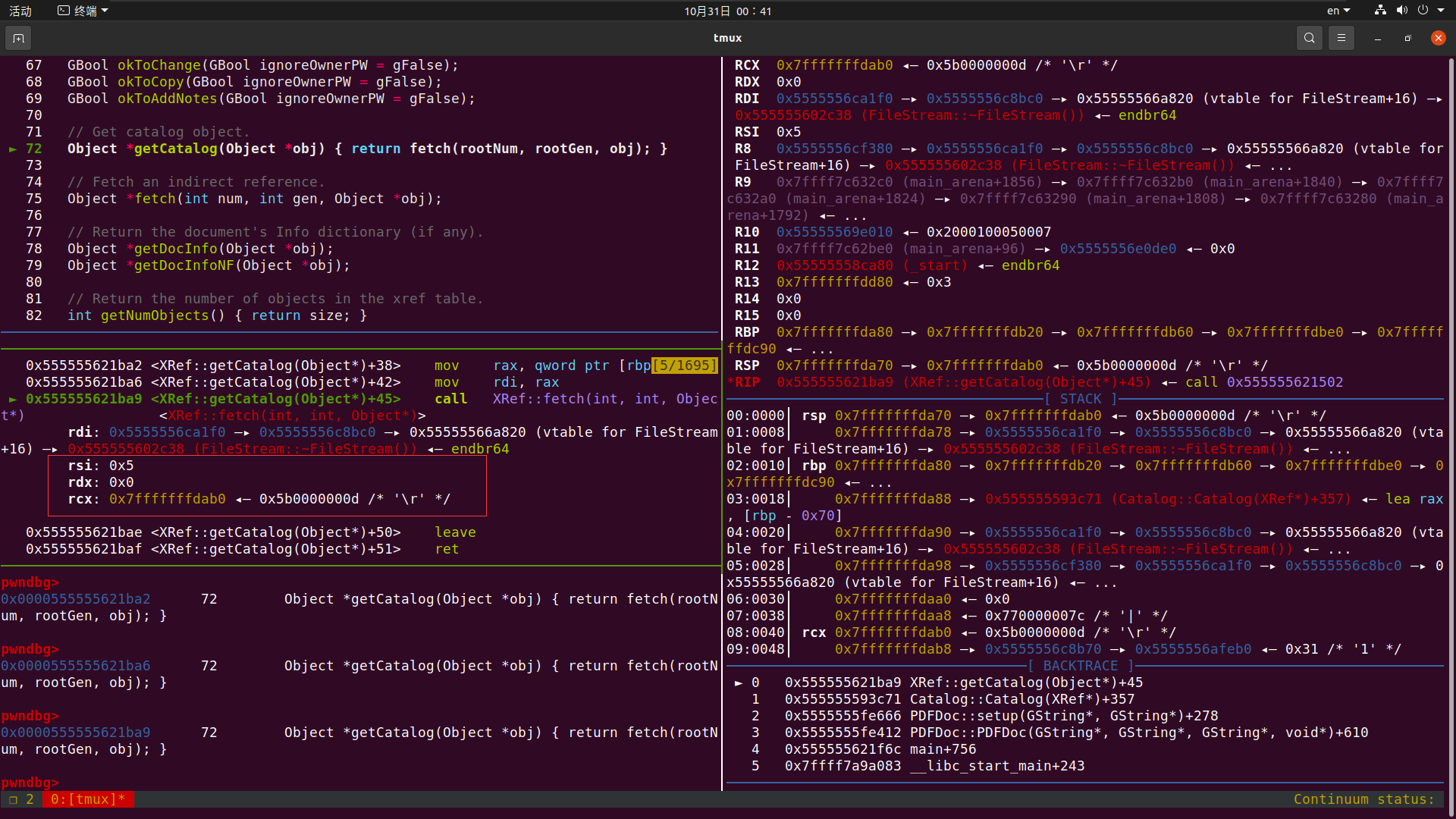
在步入以后 我们流进了xRef.cc的789行
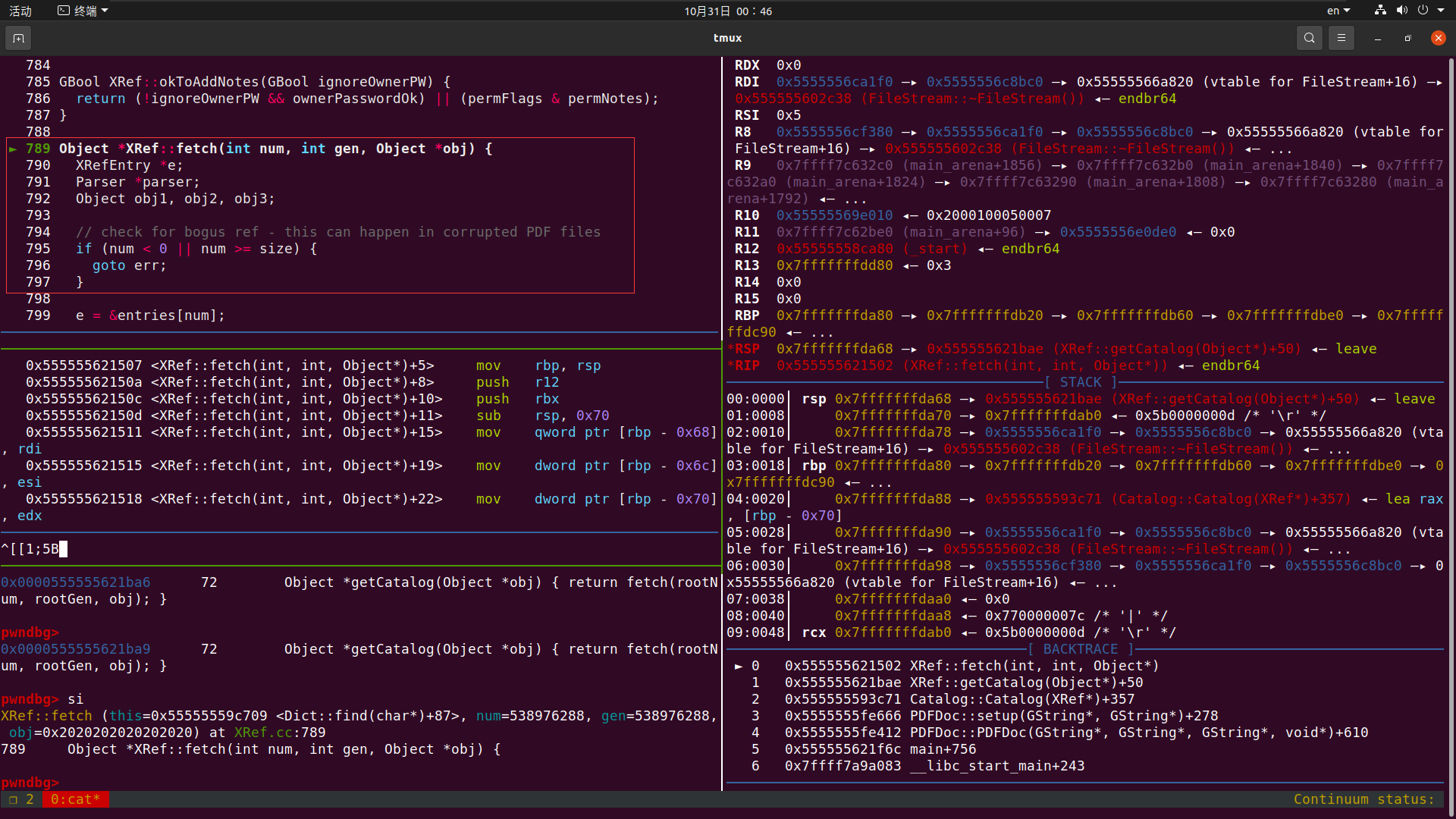
接着往下走 我们就走到了无限递归的位置
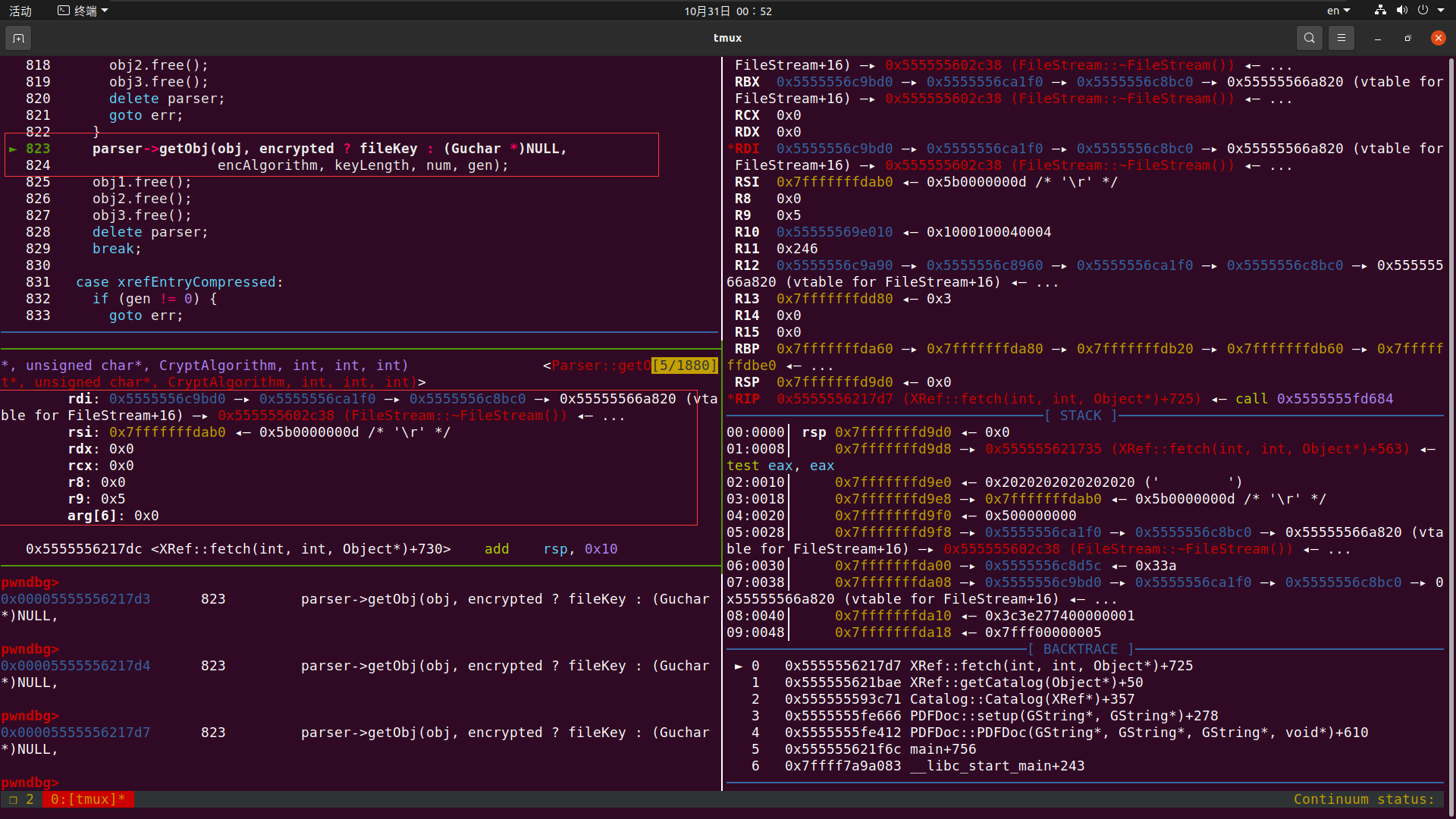
我们再进去看一下Parser—>getObj的调用过程 此时我们发现 obj重新构建了一个Dict对象
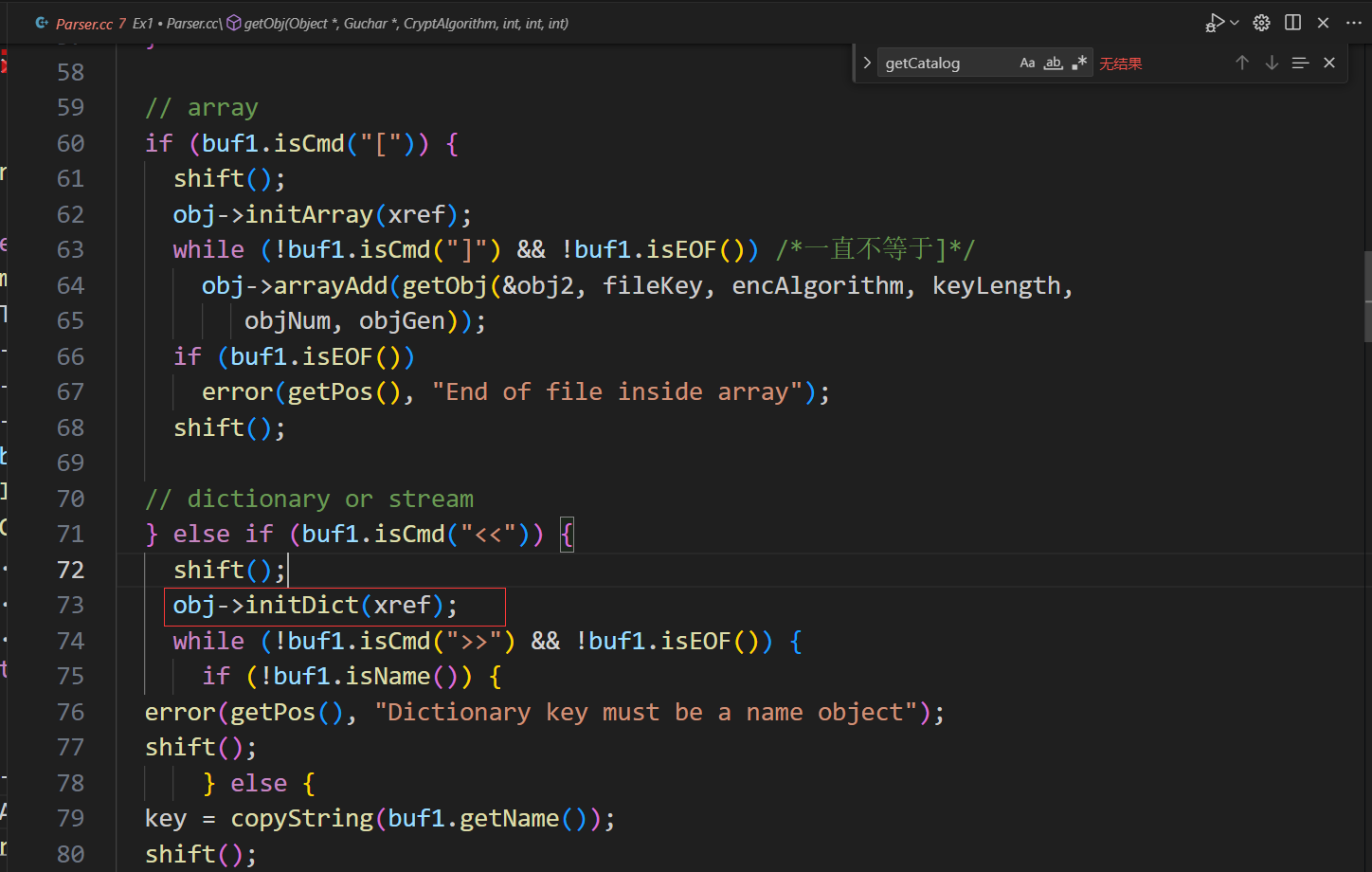
然后开始调用getObj
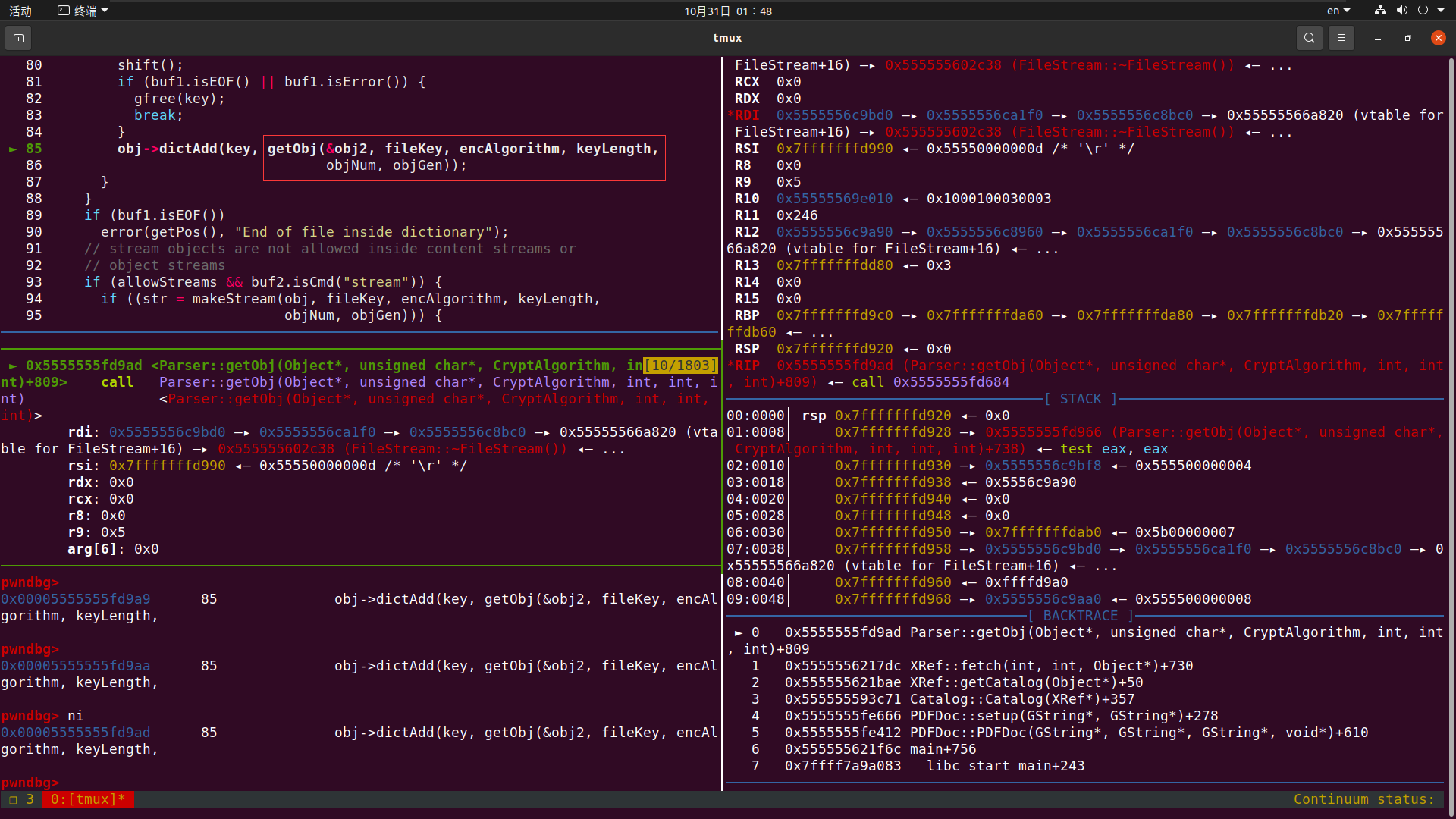
跑完循环后 我们就跑进了makeStream里(如果调试觉得太慢 调不出来 可以直接下断点去看)
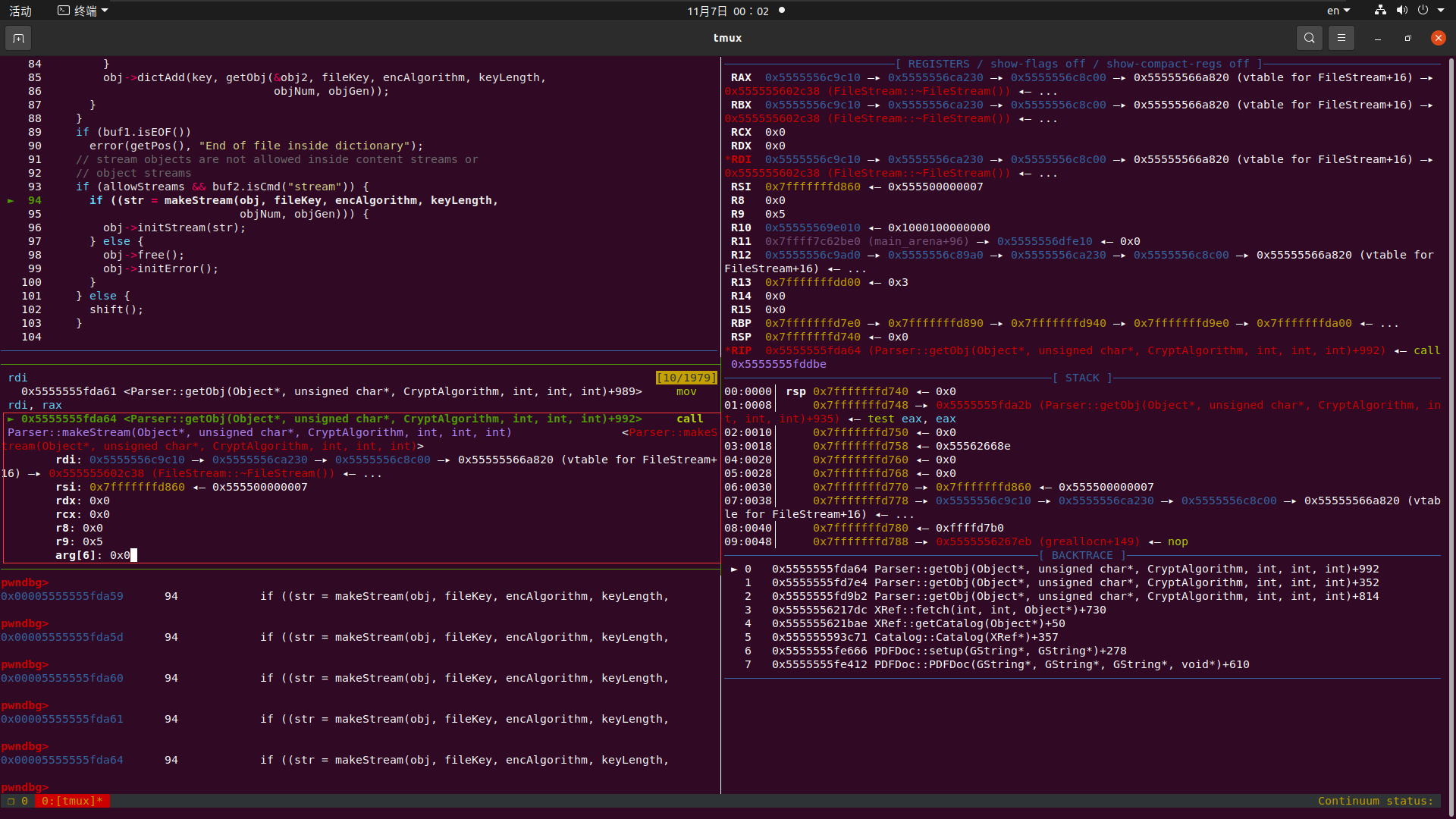
走到dict——>dictLookup进入
进入以后看到
1
2
3
| inline Object *Object::dictLookup(char *key, Object *obj)
{ return dict->lookup(key, obj); }
Object对象的dict属性中调用lookup方法 其实就是从对象Object中寻找对应key的值
|
我们又跳转进去了dict—>lookup
进入后我们发现
1
2
3
4
5
| Object *Dict::lookup(char *key, Object *obj) {
DictEntry *e;
return (e = find(key)) ? e->val.fetch(xref, obj) : obj->initNull();
}
|
我们动态进去调试一下看看
这里我们神奇的发现 原来e->val是一个objRef类型的
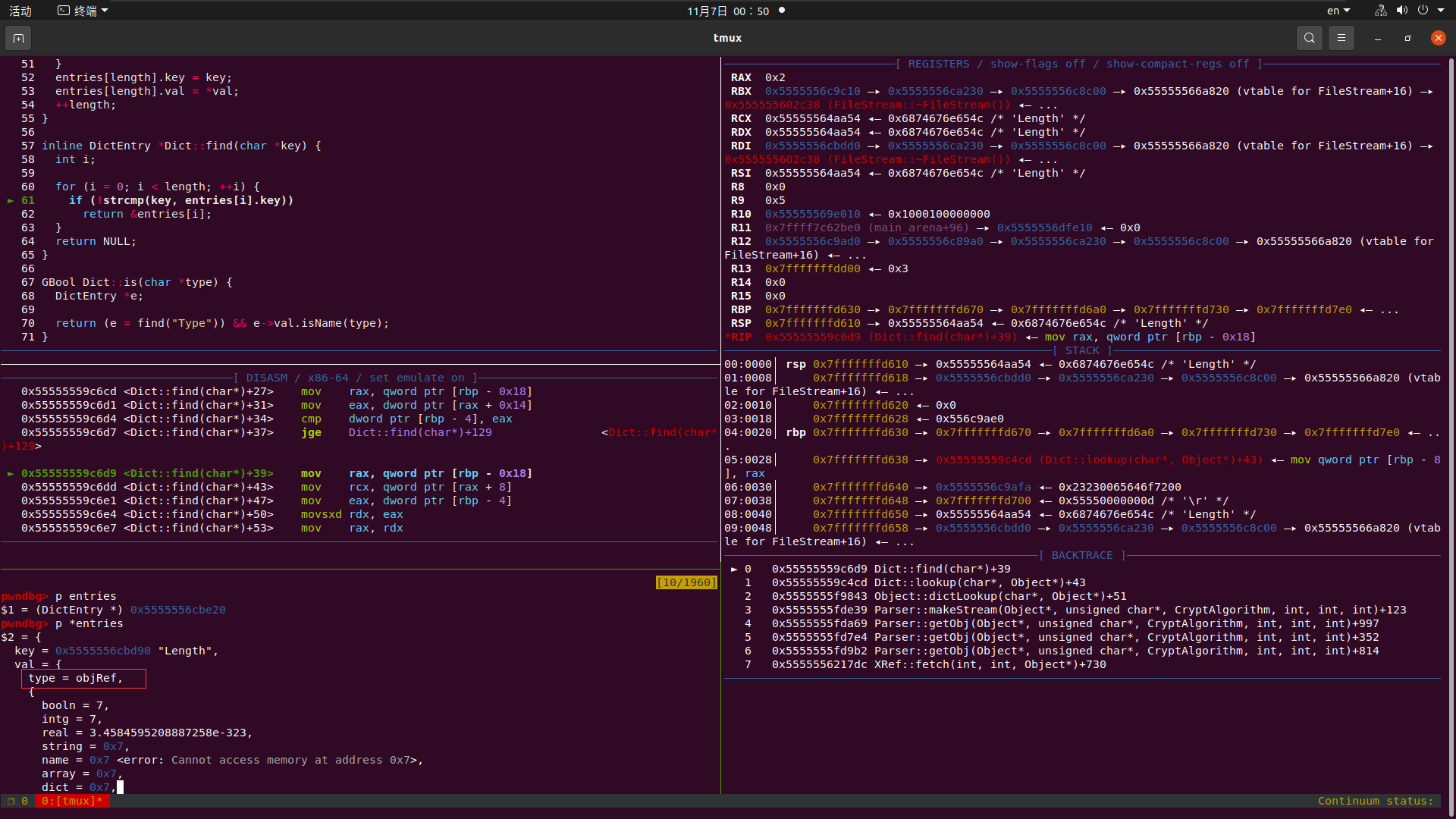
我们接着往下看
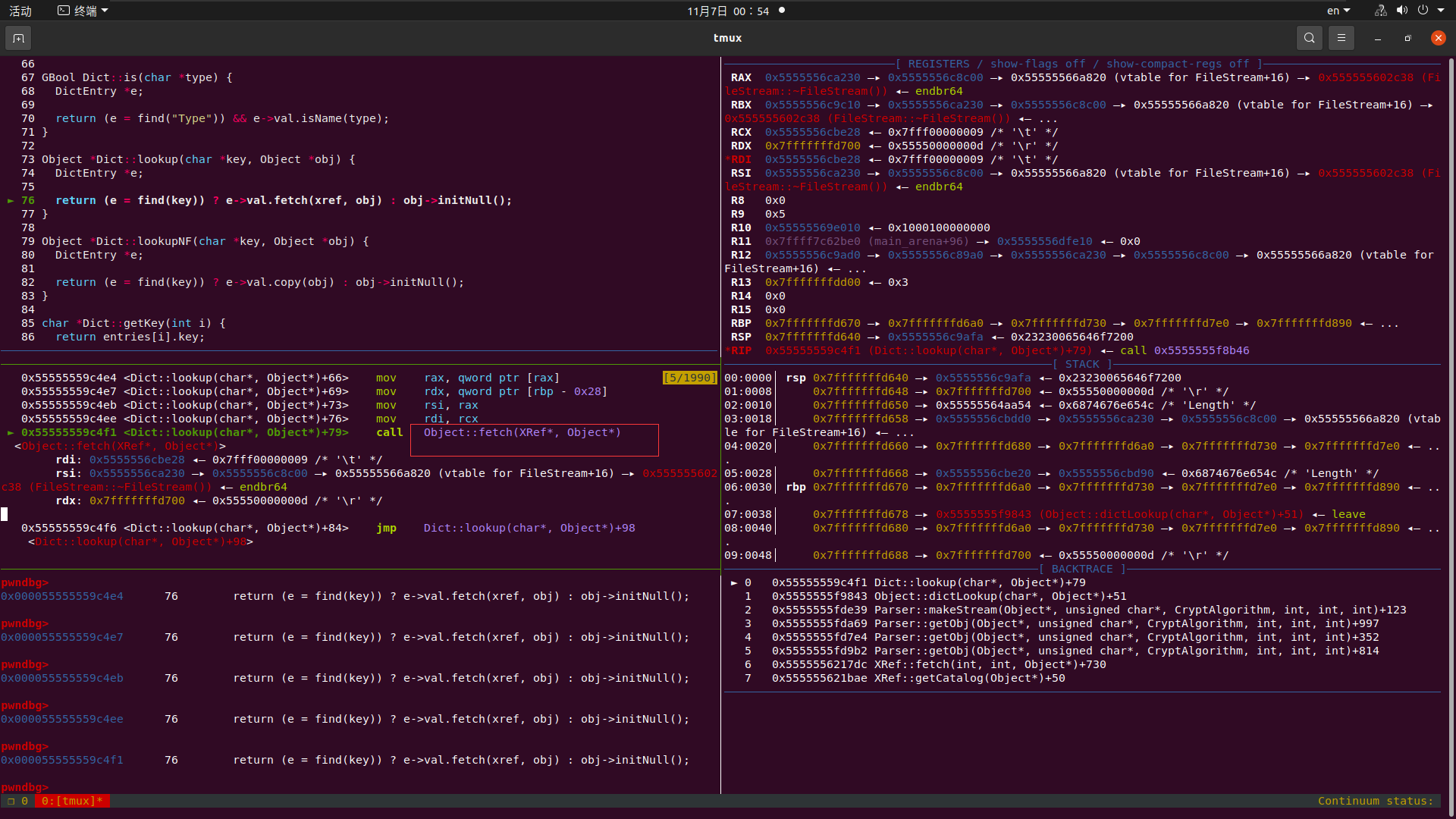
可以看到我们又跑进了Object::fetch这个函数 我们继续跟进
我们发现其参数为7,0 这也就意味着 我们又要跟着原来的过程进去了
1
| XRef::fetch(7, 0, newobj)———>Parser::getObj———>Parser::makeStream———>dict->dictLookup("Length", &obj)———>xRef->fetch(7, 0, newobj)——>.......一直循环
|
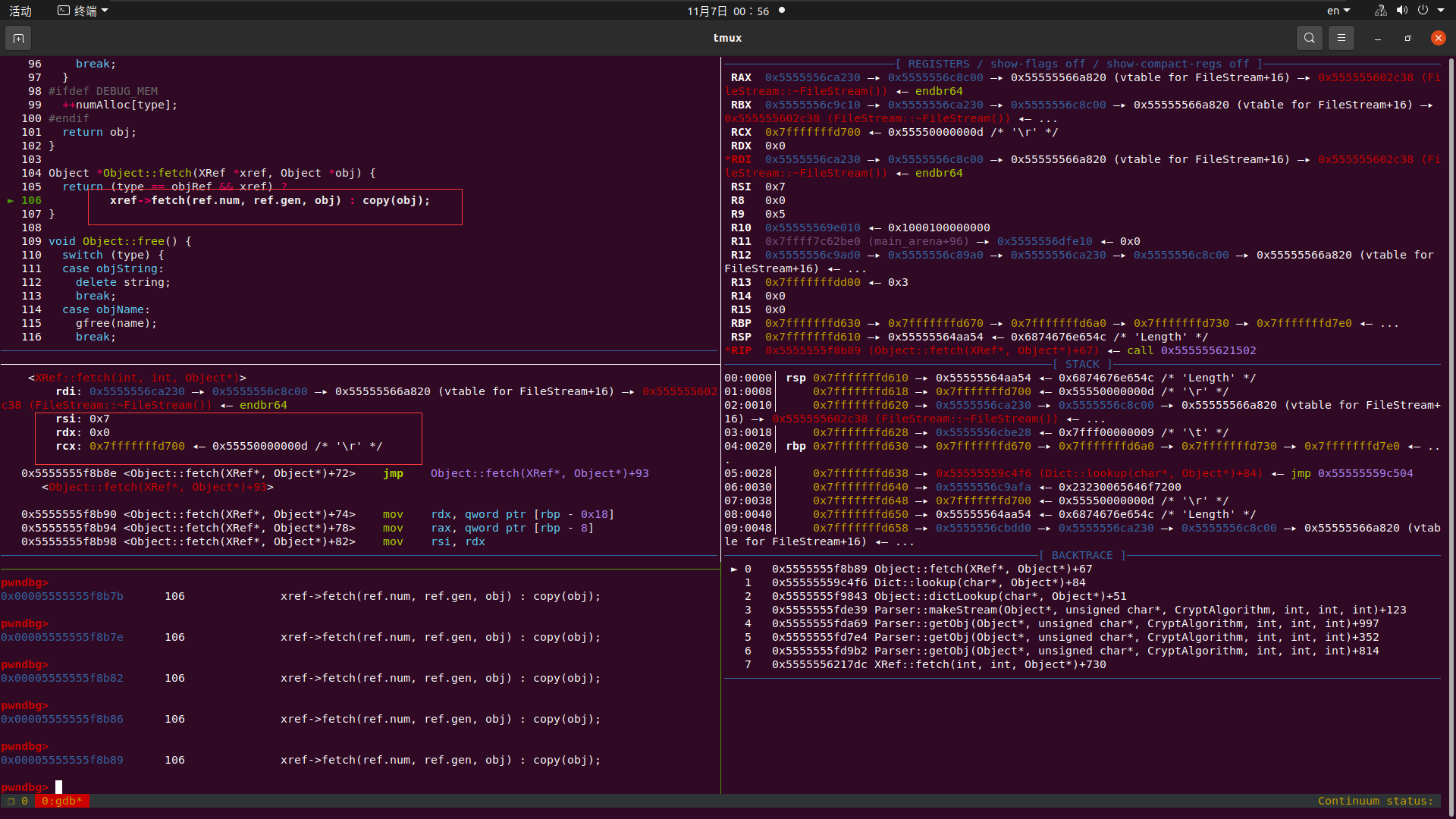
这里我们就可以发现了 我们这又调用了一遍xref—>fetch
我们接着往下跑的时候 又再次进去了xref—>fetch 发现调用的参数相同且是同一个函数 (7,0,obj) 造成了无限递归
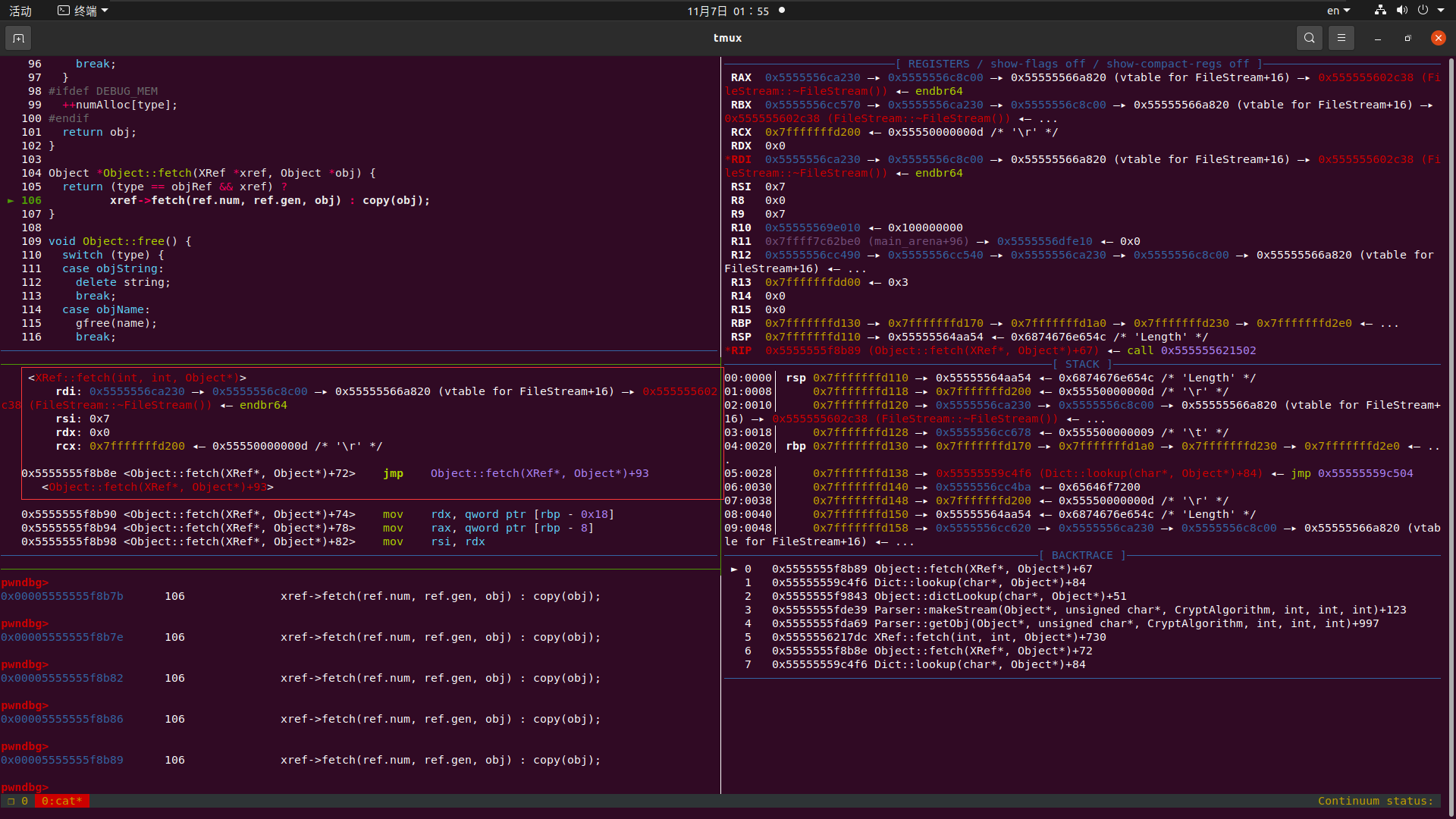
分析漏洞原因
1
| 整体修复思路也比较简单 要么限制递归次数 要么对寻找出来的e的类型进行校验即可
|
这里我们整理一下运行情况
1
2
3
4
5
6
7
8
9
10
11
12
13
| 主要是调用的 xref->fetch(7, 0, &newobj),发生了问题,至此,我们成功还原了递归链条:
1.main 经过一些过程之后,创建了一个 PDFDoc对象,并且传入了fileName,ownerPW,userPW 这里因为没有密码肯定是0
2.PDFDoc里面调用setup(ownerPassword, userPassword) ,其中读目录的时候 catalog = new Catalog(xref) 又new了一个新Catalog
3.在Catalog中调用xref->getCatalog(&catDict)
4.在Xref.h里查找 这时候我们相当于获得了一个xref::fetch
5.xref->fetch(ref.num, ref.gen, obj) 被调用,实际上 call 了 xref->fetch(5, 0, obj)
6.xref->fetch 过程中,检测到这条 entry 是未被压缩的,调用 parser->getObj(obj, fileKey=NULL, encAlgorithm=<RC4>, keyLength0, num=5, gen=0),以获取 num=5, gen=0 这个 pdf object
7.Parser::getObj 过程中,首先通过 obj->initDict(xref) 把 obj 从 objNone 初始化成一个 objDict,调用 makeStream(obj, fileKey=NULL, encAlgorithm=<RC4>, keyLength=0, objNum=5, objGen=0) 生成一个 Stream
8.Parser::makeStream 过程中,调用 obj->dictLookup("Length", &newobj),意图是从现在已经是 objDict 的 obj 里面取 key 为 "Length" 的键值对,把 value 给 newobj
9.上述 dictLookup 是一个简单封装,调用 obj->dict->lookup("Length", &newobj)
10.上述 lookup 从 obj->dict 这个 dictionary 里面寻找到 key 为 "Length" 的 entry e: (key="Length", val=<objRef>),且这里的这个类型为 objRef 的 val 的 ref 二元组为 (num=7, gen=0)。调用 val.fetch(xref, &newobj)
11.当我们接着往下面走的时候,会发现同样的,还是会进入xref->fetch(7,0,obj),至此进入了无限递归。
|
思考
根据漏洞所在位置这里 我们发现其实作者是很想obj.isInt做个判断的 但是没有判别 就已经进入循环了

改进
1.对程序做一个e的判定,其实就是思考里的内容,但是这个判断加的位置不好
2.对循环次数做一个判断,不能一直陷入循环当中